Reka 是一家位於舊金山的創新型人工智慧新創公司,由來自 DeepMind、Google 和 Meta 的頂尖研究人員創立,最近推出了名為 Reka Core 的全新多模態語言模型。這款模型被宣稱為該公司「最大也最強大的模型」,採用數千個 GPU 從零開始訓練而成。
Reka Core 目前已經可以通過 API、現場部署或裝置上部署等多種方式提供服務。作為 Reka 語言模型家族的第三個成員,Core 模型具備理解包括圖像、音頻和視頻等多種模式的能力。更重要的是,儘管該模型訓練時間不到一年,但其性能已經達到或超過了 AI 領域的多個大型企業,如 OpenAI、Google 和 Anthropic 的頂級模型水平。
Reka 公司的共同創始人兼首席執行官 Dani Yogatama 在接受 VentureBeat 專訪時表示:“我們在非常短的時間內訓練出高性能模型的能力,使公司在業界脫穎而出。”
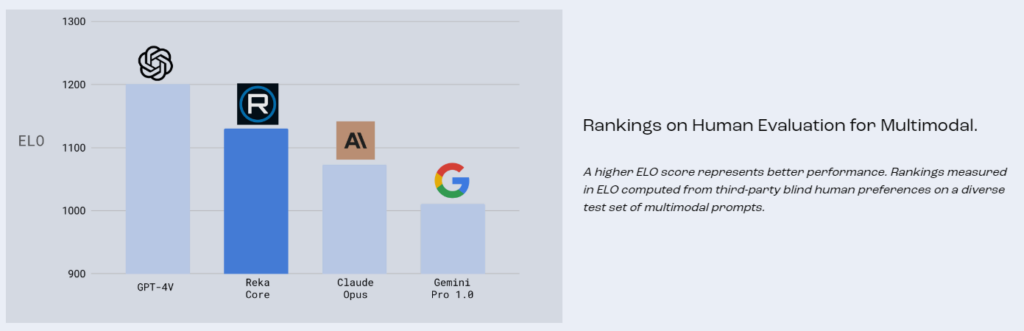
Reka 的首席科學家兼共同創始人 Yi Tay 在社交媒體 X 上透露,公司使用了“數千台 H100”GPU 來開發 Reka Core。從頭開始開發一款能與 OpenAI 的 GPT-4 和 Claude 3 Opus 競爭的模型,無疑是一項重大成就。他提到,雖然 Core 模型仍在持續改進中,但團隊對目前的表現已感到十分滿意。
Reka Core 具備哪些特點?
雖然 Reka Core 的確切參數數量尚未披露,但 Yogatama 將其描述為一個“非常大的模型”(之前的 Reka Flash 擁有 210 億個參數)。這款模型是從公開數據、授權數據和涵蓋文本、音頻、視頻及圖像檔案的合成數據中訓練而來。
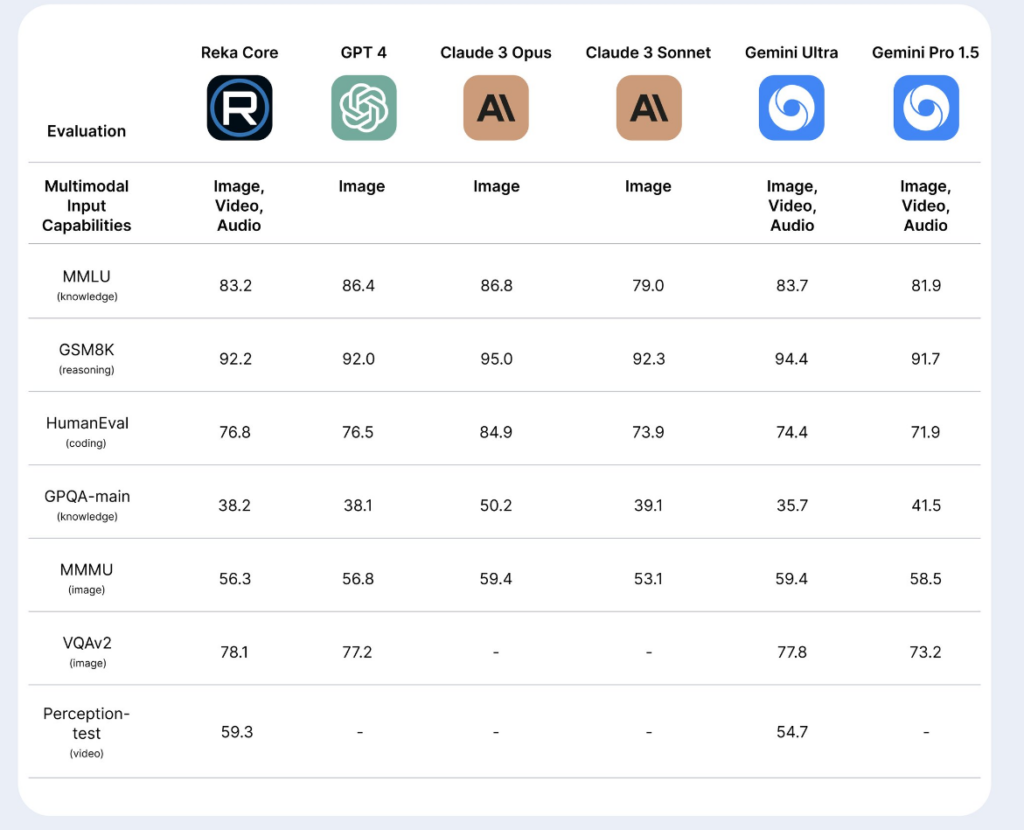
他解釋稱,這種廣泛的訓練使 Core 能夠理解多種輸入模式,並在數學和編碼等領域提供高水平的推理答案。此外,該模型還支持 32 種語言和 128,000 個標記的上下文窗口,使其能夠一次處理並吸收大量多樣的資訊,非常適合處理長文檔。 Yogatama 表示,繼 Google 的 Gemini Ultra 之後,Core 是第二個涵蓋從文本到影片的所有模式並提供高品質輸出的模型。
在視頻感知測試中,Core 的表現明顯優於唯一的競爭對手 Gemini Ultra(得分 59.3 對 54.3)。同時,在 MMMU 影像任務的基準測試中,它的得分為 56.3,僅次於 GPT-4(56.8)、Claude 3 Opus(59.4)、Gemini Ultra(59.4)和 Gemini
AI 入口:Reka Playground